科学家用数学方法分析文化演变 |
|
|
| 来源:《科学》 更新时间:2011-1-24 22:56:34 |
|
|
|
|

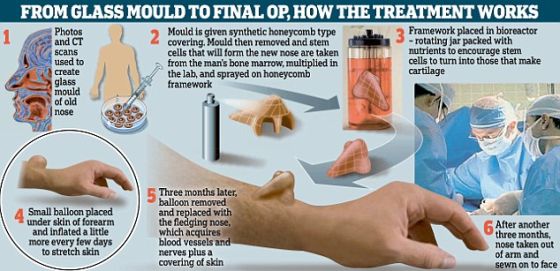
文化组学:利用数学方法分析来自谷歌图书和维基百科的海量数据,从而分析人类文化的发展和演变。(图片来源:《科学》杂志)
来自哈佛大学的一个研究小组借助对基因组海量数据进行分析的数学方法,对来自谷歌图书项目的数据进行了分析,发现了单词或人名随时间变化的出现频率,并由此推导出人类文化的发展趋势和演变规律,他们的第一批成果发表在新出版的《科学》杂志上。
哈佛大学数学博士生艾略兹·利波曼·埃顿(Erez Lieberman Aiden)和同学简-拜普提斯特·迈克尔(Jean-Baptiste Michel)是这个项目的负责人。埃顿说:“如果单词被认为是一个文化单元,那么这种方法就是有意义的,基因组里包含了可继承的信息,世代相传。在我们的书中,我们使用的单词也代代相传。”
为了向数据密集型的基因组学表示敬意,迈克尔和埃顿将这个全新的领域称为“文化组学”,这是一个由文化(culture)和基因组学(genomics)合成的新词。如今,谷歌正在www.culturomics.org上推出一种新应用,允许任何人访问和分析完成的数据库,该数据库包含了20亿单词和短语。
“这不是一个疯狂的想法”
该项目始于3年前。
当时,埃顿正在用数学的方法研究基因组学。2007年3月,他来到谷歌公司位于加州山景城的总部,敲响了谷歌研究部主任彼特·诺维格(Peter Norvig)的办公室,目的是希望得到一些数据,并且能进入谷歌图书系统。谷歌图书是谷歌公司一项雄心勃勃但又有争议的项目:扫描人类出版的每一本书的每一页。
埃顿认为,通过分析过去几个世纪文字或单词在出版物中的增长、变化和衰落,研究人员有可能在大范围内研究文化的演变。诺维格说:“我不认为这是一个疯狂的想法,我们(的谷歌图书项目)正在扫描书籍,因此,我们应该有数据。”
但是,谷歌图书的法律问题使得这个项目几乎不能启动;因为许多书受到版权保护,还有出版人和作者向法院起诉谷歌图书项目。诺维格承认,他担心分享数字图书的合法性,因为如果没有对作者进行补偿,这些图书是不能传播的。但埃顿提出一个想法:将这些扫描图书的文本转化为单个巨大的语言模型N-Gram数据库,这将是一篇贯穿于整个人类历史时期的文本,其中包含频繁出现的词语,学者因此能够在不实际读书的情况下量化研究这些书。这些理由足以说服诺维格。
埃顿和迈克尔组成团队。他们将进化生物学中的数学工具用于书面语言的研究,比如,2007年,他们对英语动词演变的研究登上了《自然》杂志的封面,但是,他们从未挑战过谷歌图书所容纳的海量数据。目前,谷歌图书拥有来自1500万册图书的20万亿词汇,这些图书量相当于自1450年古登堡《圣经》出版以来人类所出版图书量的12%。
古登堡《圣经》是西欧第一本印刷书籍,从传播学的角度看,工业生产方式的诞生或许应该从古登堡《圣经》的印刷算起。古登堡金属活版印刷术的发明,大大提升了书籍印刷的速度,降低了印刷成本,加速了知识和信息的传播。
通过对比分析,埃顿和迈克尔发现,人类基因组的信息量只相当于一首有30亿个字母的诗篇。
他们还量化分析了历史长河中个人对文化的影响。比如,对“西格蒙德·弗洛伊德”(奥地利精神分析学家)和“查尔斯·达尔文”(英国生物学家)出现频率的分析,揭示出文化智力持续演变的趋势:在2005年,弗洛伊德已经失去阵地,达尔文最终超越了他。
对“N-Gram ”数据库的分析还揭示出被历史学家们忽视的模式。埃顿的妻子、哈佛医学院学生帕瑞斯[1] [2] 下一页
|
上一篇科学技术: 研究宣布实现用光控制蠕虫意识
下一篇科学技术: 晶体中量子纠缠态信息存储成功 |
|
|
|
|