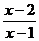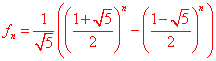�������ճ������У����������ĸ��������ࡣһ���������ĸ�������Ƿ����������������ȷ�ġ����磻�ˡ���Ȼ���������εȵȡ�Ҫô���ˣ�Ҫô�����ˡ�Ҫô����Ȼ����Ҫô������Ȼ����Ҫô�������Σ�Ҫô���������Ρ���һ������������Ľ�����ģ���ģ����ж��˵�˼ά���������磺���������粻�磿�����˲����ˣ��ȵȡ���ʩ���ҹ��Ŵ����ϵ���Ů���е��ǡ������������ʩ���������˵����һЩ�˿���δ����ô�����ˣ�����һЩ�����ȴ���ÿ�������ʩ����⡣�ɼ����������롰�������Dz�����һ����ȷ�Ľ��ġ���˵���硱�롰���硱���峿��㣬����Ϊ���С���ױ��硱��������˵�������dz��ˣ����Դ����Сѧ��˵��ȴ�Ǻ������ġ����ڱ��˲����ˣ��Ǹ������˵ĸо������ˣ��ڿ������У�����������ģ������Ҫ�����������öࡣ��������ģ������ȥ���е���ѧģ���������ã���Ҫ�γ��µ����ۺͷ�����������ѧ��ģ������֮�����һ��������������������Ҫ���ġ�ģ����ѧ����
����
����������������������Ǽ������ѧ��Ѹ�ٷ�չ�����֪�����˵Ĵ��Ծ��зǷ����б�ʹ���ģ�����������������һ������ʶ���Լ���ĸ��Ϊ������ʹ��λĸ���������£��ı��˷�ʽ�����ĺ�����Ȼ��Ӹ߰������ݡ����ݡ���̬��Ѹ�ٵ�����ȷ�жϡ����������ü�������ɣ��Ǿͷǵð���λĸ�����ߡ����ء������ٶȡ��������ߵȵȣ�ȫ�����㵽С������ʮ��λ��Ȼ����������жϡ������ġ���ȷ��ʵ��������ԸΥ���ߵ�������ķ��档˵��������Ϊ��λĸ������һʱ����һ��С�ܣ��ò�λ��ƽ���߶ȣ���ԭ����������㼸���ף���ʹ������������ܾ����ܡ����ж��أ��ѹ�ģ����ѧ�Ĵ�ʼ�ˣ��������������Ǵ�ѧ���ڡ��Կ�ר�����£�L.A.Za-deh��˵��������Ե�ϵͳԽ���ӣ����Ƕ�������������ľ�ȷ��������Խ�͡����������ؾ���һ��ͣ����������ӣ���˵��Ҫ������ͣ��ӵ��ͣ������������������֮��Ŀյ��ϣ�����о����˾����˵������ʲô���¡������þ�ȷ�ķ�����⣬��ʹ��һ̨���͵��Ӽ����Ҳ�����á�
����
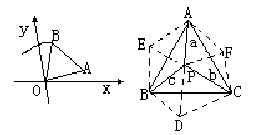
������ô��Ҫʹ������ܹ�ģ�����ԣ��Ը���ϵͳ����ʶ����жϣ���·�������أ����½������ŴӾ��ȷ��桰���ˡ�һ�������������������ʹģ��������ѧ�������硰ͺͷ��������Ȼ��һ��ģ�������ͼ������ͷ�������͡���a����ͷ��«���⣬��������ͺͷ���������̶�Ϊ1����d����ͷ�ǵ��͵�ͺ�������ԡ�ͺ���������̶ȿɶ�Ϊ0.8����c����ͷ�ϣ��������ںڵ�ͷ���������롰ͺ��մ���ϱߣ����ԡ�ͺ���������̶�Ϊ0����b���루c���ġ�ͺ������֮��a������d�����㣬��֮��c�������࣬�����̶ȿɷֱ�Ϊ0.5��0.3��������ͺ�����ģ������Ϳ��������µķ��������ظ������壺
����
����[ͺͷ]��1/a��0.5/b��0/c��0.8/d��0.3/e
����
��������ġ������͡�/��������ͨ������Ӻ��������ֻ��һ�ּǺš���1/a������״̬a�������̶�Ϊ��1���ȵȣ����������ʾ��������IJ��С�
����
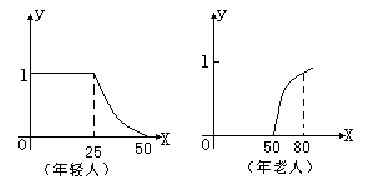
�������������ٿ������ᡱ�͡����ϡ�������ģ��������½��ڱ��˸���ͳ�����ϣ�������������������������ͼ��ͼ�к������ʾ���䣬�������ʾ�����̶ȣ����磬������ͼ���Կ�����50�����µ��˲����ڡ����ϡ����������䳬��50��ʱ�������������������ϡ��������̶�ҲԽ��Խ��������ʮ����ϡ����70����ˡ����ϡ��������̶��Ѵ�94����ͬ����������ͼ�����ǿ��Կ�����25�����µ��ˣ������ᡱ�������̶�Ϊ100��������25�꣬�����ᡱ�ij̶�Խ��ԽС��40�����ǡ��˵����ꡱ�������ᡱ�������̶�ֻ��10����
����
���������������㣺�������ѧ��ʦ�����𣿡�����Ļش�ȴ�ǣ����������������̶�Ϊ25�����������Ĵ���Ȼ�����д�������Ȼ�Ǻܱ�Ť�ġ�Ϊ��ʹ�˲���һ��ȷ�е�ӡ�����ǿ��Թ̶�һ���ٷ���������40���������̶ȴ��ڻ����40���Ķ��С����ᡱ����֮�Ͳ��С����ᡱ��������ǰ���£���������ѵĻش�Ҳ���ǿ϶����ˣ���������ظ���������ѣ������ѧ��
[1] [2] ��һҳ